웹이 어떻게 작동하는지 이해해야 하는 이유
현대 디지털 환경에서 다양한 온라인 서비스를 효율적으로 활용하기 위해서는 기본적인 웹의 작동 원리를 이해하는 것이 필수적입니다. 특히 MAKE와 같은 자동화 도구를 활용해 네이버 메일, 구글 시트 등의 외부 서비스를 연동하려면, 웹이 어떻게 요청을 주고받으며 데이터를 처리하는지에 대한 개념이 확실히 잡혀 있어야 합니다.
예를 들어, 크롬이 웹사이트를 로딩하는 과정과 MAKE가 API를 통해 데이터를 불러오는 과정은 구조적으로 매우 유사합니다.
1. 웹 주소 입력부터 DNS 서버 조회까지 (편의점 검색):
우리가 크롬(혹은 다른 웹 브라우저)에 웹 주소를 입력하는 순간, 크롬은 마치 여러분이 스마트폰으로 편의점 위치를 검색하는 것과 동일한 작업을 시작합니다.
바로 DNS(Domain Name System) 서버에게 해당 웹 주소(예: naver.com)에 해당하는 실제 서버 주소를 물어보는 것이죠.
DNS 서버는 웹의 주소록 역할을 하며, 우리가 기억하기 쉬운 도메인 이름을 실제 컴퓨터가 이해하는 IP 주소로 변환해 줍니다.
이 과정을 통해 크롬은 네이버 홈페이지가 위치한 서버의 '진짜 주소'를 알게 됩니다.
2. HTTP 요청 전송 (편의점에서 물 찾기):
크롬이 네이버 서버의 실제 주소를 알게 되면, 이제 네이버 서버로 HTTP(HyperText Transfer Protocol) 요청 메시지를 보냅니다. 이는 마치 여러분이 편의점 위치를 파악하고 편의점으로 걸어가서 물을 찾아보는 과정과 같습니다. 이 요청 메시지에는 네이버 홈페이지의 내용을 보여달라는 명령이 담겨 있습니다.
3. 데이터 패킷 전송 (물 계산대로 가져가기):
네이버 서버는 크롬의 HTTP 요청을 받으면, 요청받은 홈페이지의 내용들을 데이터 패킷이라는 작은 덩어리들로 나누어 크롬에게 전송하기 시작합니다. 이 데이터 패킷들은 마치 여러분이 편의점에서 물을 찾아 계산대로 가져가는 것과 같습니다. 각 패킷에는홈페이지를 구성하는 이미지, 텍스트, 코드 등의 디지털 정보(바이트: 101101000100…)가 담겨 있습니다.
4. 웹 페이지 조립 및 표시 (물 계산하고 마시기):
크롬은 네이버 서버로부터 전송받은 이 작은 데이터 패킷들을 하나하나 받아 완전한 네이버 홈페이지로 조립합니다. 그리고 최종적으로 이 완성된 웹 페이지를 여러분의 화면에 보여줍니다. 이는 마치 여러분이 계산을 마치고 시원한 물을 마시는 과정과 같습니다.
HTTP 요청 전송의 의미와 작동 원리
웹 브라우저가 DNS 서버로부터 IP 주소를 획득하면, 그다음 단계는 해당 주소로 HTTP 요청을 보내는 것입니다. HTTP(HyperText Transfer Protocol)는 클라이언트가 서버에 정보를 요청할 때 사용하는 표준 프로토콜입니다. 다시 말해, 크롬이 ‘이 주소로 가서 홈페이지 내용을 보여달라’고 요청하는 메시지를 서버에 전달하는 과정입니다.
이 작업은 마치 여러분이 편의점에 직접 찾아가 물을 찾는 행위에 비유할 수 있습니다. 브라우저는 GET 요청을 통해 ‘이 웹페이지를 주세요’라고 말하고, 서버는 해당 요청을 받고 준비된 콘텐츠를 응답합니다. 이때 요청 헤더에는 여러 가지 정보(브라우저 종류, 언어 설정, 쿠키 정보 등)가 함께 전송되어, 서버가 상황에 맞는 데이터를 돌려줄 수 있도록 도와줍니다. API 요청도 마찬가지로 이와 유사한 HTTP 요청을 보내며, 정확한 헤더 및 인증 정보를 포함해야 올바른 응답을 받을 수 있습니다. 이를 이해하면 자동화 작업 시 어떤 정보가 반드시 포함되어야 하는지 스스로 판단할 수 있게 됩니다.

데이터 패킷 전송과 웹 페이지 조립 과정
HTTP 요청을 받은 서버는 웹페이지의 데이터를 준비해서 MAKE에게 돌려보냅니다. 그런데 이 데이터는 한꺼번에 전송되지 않습니다. 서버는 전체 데이터를 작은 단위인 ‘데이터 패킷’으로 나누어 순차적으로 전송합니다.
각 패킷에는 이미지, 텍스트, 스타일 정보, 자바스크립트 코드 등 웹사이트를 구성하는 여러 요소들이 담겨 있습니다.
이 과정은 마치 편의점에서 물을 찾아 계산대로 하나씩 가져오는 것과 유사합니다. 크롬은 이렇게 받은 수많은 패킷을 다시 조립하여 화면에 완성된 웹페이지를 표시합니다.
이 조립 과정은 렌더링 엔진을 통해 수행되며, HTML, CSS, JS 등의 파일을 해석하고 시각화하는 역할을 합니다.
MAKE 자동화 도구에서도 API 응답으로 받은 JSON 데이터나 XML 데이터를 해석하고 원하는 정보만 추출하는 로직이 필요한데, 이는 웹 페이지 조립 원리와 동일한 개념입니다. 이러한 원리를 알고 있다면, 데이터 포맷이 복잡하거나 구조가 바뀌어도 쉽게 응용할 수 있습니다.
이러한 웹의 도식화된 구조를 머릿속에 가지고 있어야 하는 이유는 단순히 기술적인 호기심을 넘어, MAKE와 같은 자동화 도구를 활용하여 구글 시트 등 다양한 서비스 간의 API(Application Programming Interface) 연결을 깊이 이해하고 응용할 수 있기 때문입니다.
예를 들어, MAKE가 하나의 크롬과 같다고 생각해 보세요.
MAKE가 구글 시트에서 제목이나 내용을 불러오려면 내부적으로 DNS 서버에게 구글 시트의 정보가 있는 곳의 주소를 물어보고, 해당 주소로 "제목과 내용을 보내달라"는 요청을 보내야 합니다.
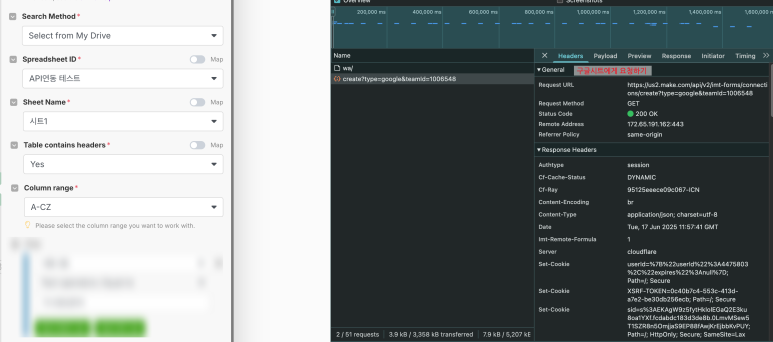
이를 위해서는 구글 시트의 "진짜 주소"를 파악하기 위한 정보(API 키, 인증 정보 등)가 필요하며,
여러분은 이 정보를 MAKE에게 정확하게 입력해야 합니다.
MAKE에게 주황색을 보이는 트리 구조 결과값 를 보내줘서 화면에 SpreadsheetID: API연동테스트 SheetName :시트1이 나타나게 되는겁니다

MAKE에게 구글시트을 실행시키면 자바스립트가 동작하는데 이것또한 웹 작동방식과 동일한 작동원리입니다

MAKE에게 주황색을 보이는 트리 구조 결과값 를 보내줘서

MAKE 화면에 제목: MAKE 자동화가 무엇인가? 내용: 2. Make.com (구 Integromat)을 이용한 업무 자동화... 이 나타나게 되는겁니다

이러한 기본적인 개념을 이해하고 있다면, 단순히 MAKE 자동화(구글 시트에서 제목, 내용을 불러와 스레드에 적용하는 것)를 튜토리얼을 따라 하는 것을 넘어, 충분히 혼자서 원하는 자동화 시나리오를 만들고 응용할 수 있는 능력을 갖추게 될 것입니다.
결론
웹의 작동 원리를 이해하는 것은 단순한 지식 축적을 넘어, 실전에서 복잡한 작업을 자동화하고 디지털 환경을 효과적으로 활용하기 위한 기초 체력을 키우는 과정입니다.
예를 들어, 구글 시트에서 데이터를 불러오고 네이버 메일에 자동으로 전송하는 시나리오를 만든다고 가정해보겠습니다.
이때는 MAKE에게 구글 시트에서 제목과 내용 데이타를 가져오라는 요청을 보내고,
응답받은 데이터를 구조화해서 위의 그림처럼 화면에 보여지고,
이 반대로 네이버 메일에게 구글 시트 제목과 내용 데이타를 구조화해서 보낸다는 요청을 보내고,
응답받으면 구글시트 데이타를 보내는 흐름을 이해해야 합니다.
이 모든 과정에서 공통적으로 다른 프로그램과연결 를 바탕으로 이루어집니다.
1~4 단계별 작동 방식을 이해하고 있다면,스스로 응용 가능한 MAKE 자동화 생태계를 구축할 수 있습니다.
결국, 이처럼 웹의 작동 방식을 익히는 것이 MAKE 전문가로 성장하는 데 결정적인 밑거름이 됩니다.
'부업스토리' 카테고리의 다른 글
| MAKE 자동화의 본질를 생각하며 (1) | 2025.06.18 |
|---|---|
| 비개발자도 AI로 돈 버는 바이브코딩 (4) | 2025.06.15 |
| 입력필드 커스터마이징을 통한 KBoard 등록 페이지 최적화 (0) | 2025.06.15 |
| Make를 활용한 워드프레스 자동 포스팅 (6) | 2025.06.15 |
| 스마트메이커 앱프로듀서 뒤집어보기 2 (0) | 2025.05.01 |